



Is RAG Really Dead? Three Arguments from the Industry
The Tension between RAG and "Just Stuff it in the Context Window"


It seems there is no week—or almost no day—without a debate over Retrieval-Augmented Generation (RAG). Last week was no different. Let's dive into three of the most heated discussions that unfolded, but before that, have you already signed up at AI Product Engineer? We are starting our course on building AI Agents with Langgraph and you don't want to miss it! So just go to https://aiproduct.engineer/signin/signup to create your account and stay informed. With that said, let's look at what we will cover this week:
First, we have Richard Meng's sharing that every single company he spoke with—-30 in total-—has failed at implementing RAG-based chatbots for PDFs. His conclusion? Scrap RAG entirely in favor of direct document feeding into LLMs. But as the discussion unfolded, skeptics pointed out major gaps in his reasoning.
Second, Paolo Perrone declared that "Google Just Killed RAG," arguing that Gemini 2.0's expanded context windows render RAG obsolete. He shared a blog post claiming to have parsed 6,000 pages for just $1, but this claim sparked a fierce debate over the practical limits of long-context models and whether they can truly replace retrieval systems at scale.
Finally, Nicolay Christopher Gerold dropped a reality check on the long-context hype. Citing the NoLima benchmark, he revealed that model accuracy sharply declines with increasing token lengths, undermining the idea that massive context windows alone can solve document retrieval problems. His argument? Instead of choosing between RAG and long contexts, the future lies in hybrid approaches that balance both.
With these three threads shaping the conversation, let's break down the arguments, the evidence, and what it all means for us AI Product Engineers.
1️⃣ When "Keep It Simple" Is Too Simple
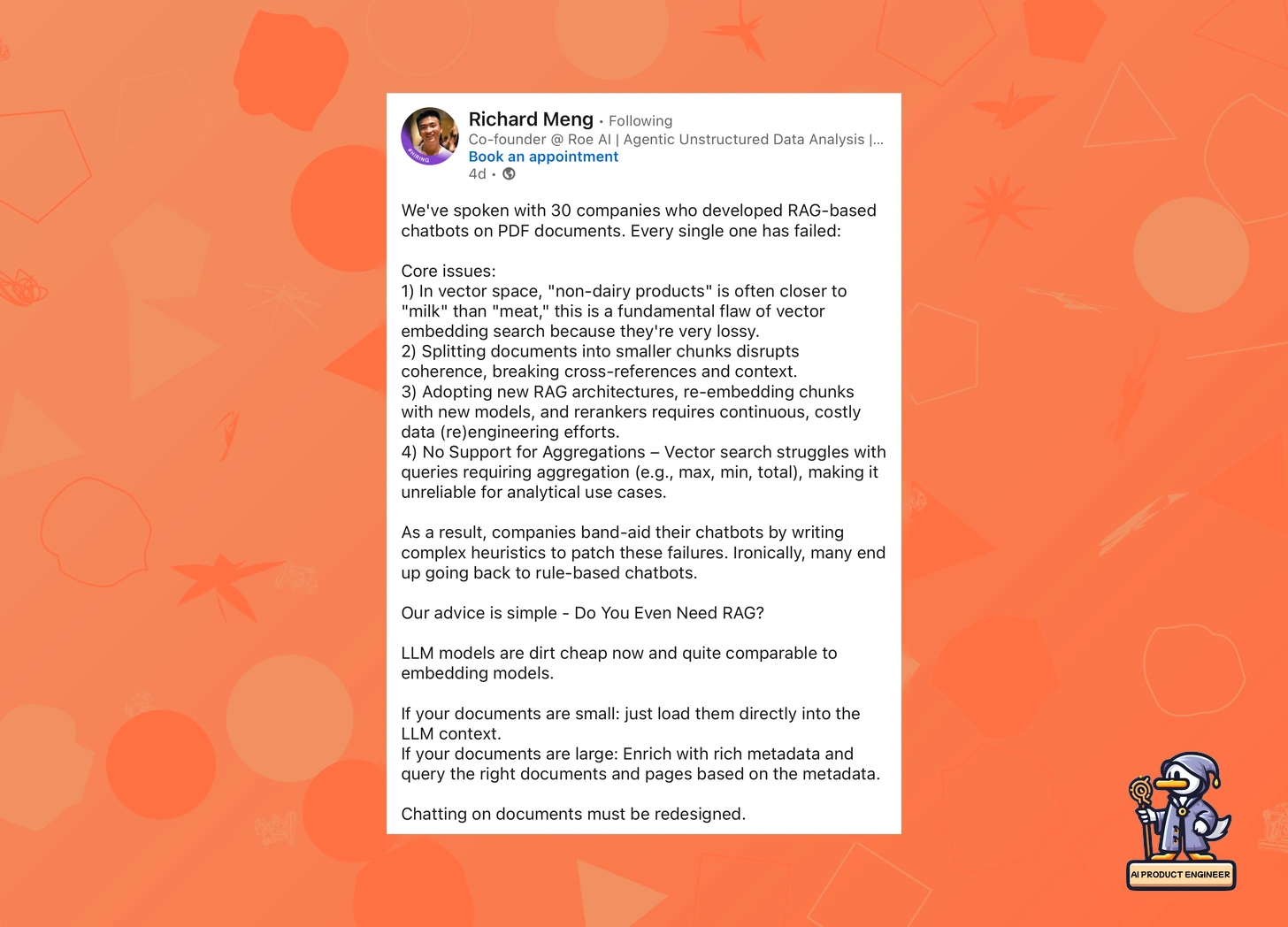
Richard Meng dropped what he likely thought was a truth bomb: every single company he's spoken to—-30 in total—-has failed at implementing RAG-based chatbots for PDFs. No exceptions. His conclusion? Scrap RAG entirely. But hold up—something doesn't add up.
Richard's argument is straightforward: vector embeddings make basic mistakes, document chunking destroys context, and maintaining RAG systems is too costly. His proposed alternative? Just feed documents directly into LLMs (they're cheap now!) or rely on metadata for larger docs. This statement triggered a flurry of opinions.
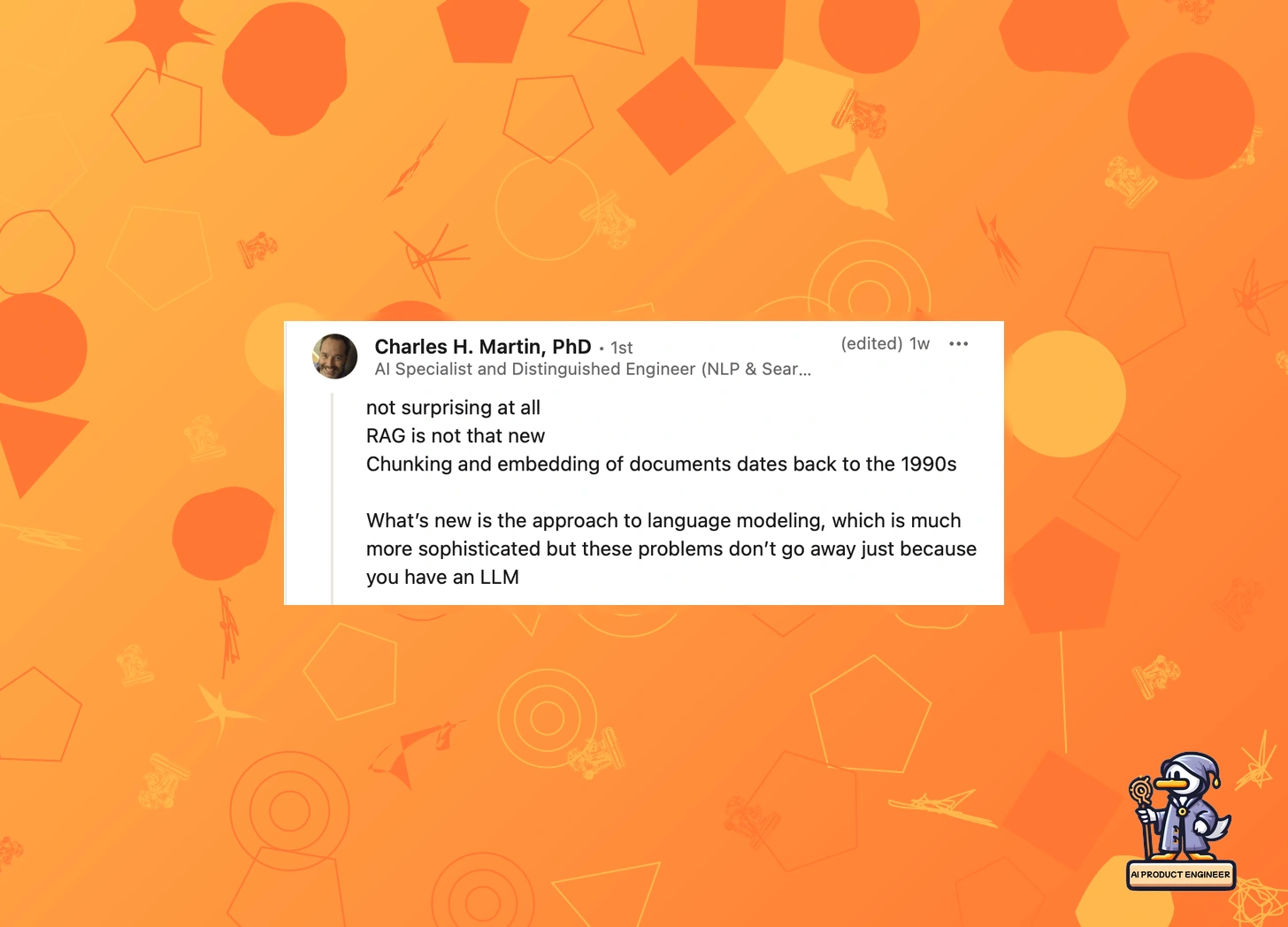
Very quickly, the comments section erupted. AI engineers flooded in, many echoing Richard's sentiments: "Finally, someone said it!" Charles H. Martin—who's been around since vector embeddings were in their infancy and a known voice in the ML space—was quick to chime in with an "I told you so," arguing these issues have been known since the '90s but keep resurfacing under new terminology.
But the most compelling responses weren't necessarily from the cheerleaders—they were the skeptics poking holes in Richard's logic. We were also in that camp. Here, we pointed out: "How do we generate this metadata without some form of chunking, vector embeddings, or RAG to seed it?" It's a chicken-and-egg problem that Richard sidesteps.
And about that "LLMs are cheap now" claim—sure, that works if you're dealing with a handful of documents. But as several practitioners noted, try loading thousands of pages into an LLM's context window and watch costs skyrocket. Not to mention the "lost in the middle" problem when LLMs struggle to retain key information across massive contexts.
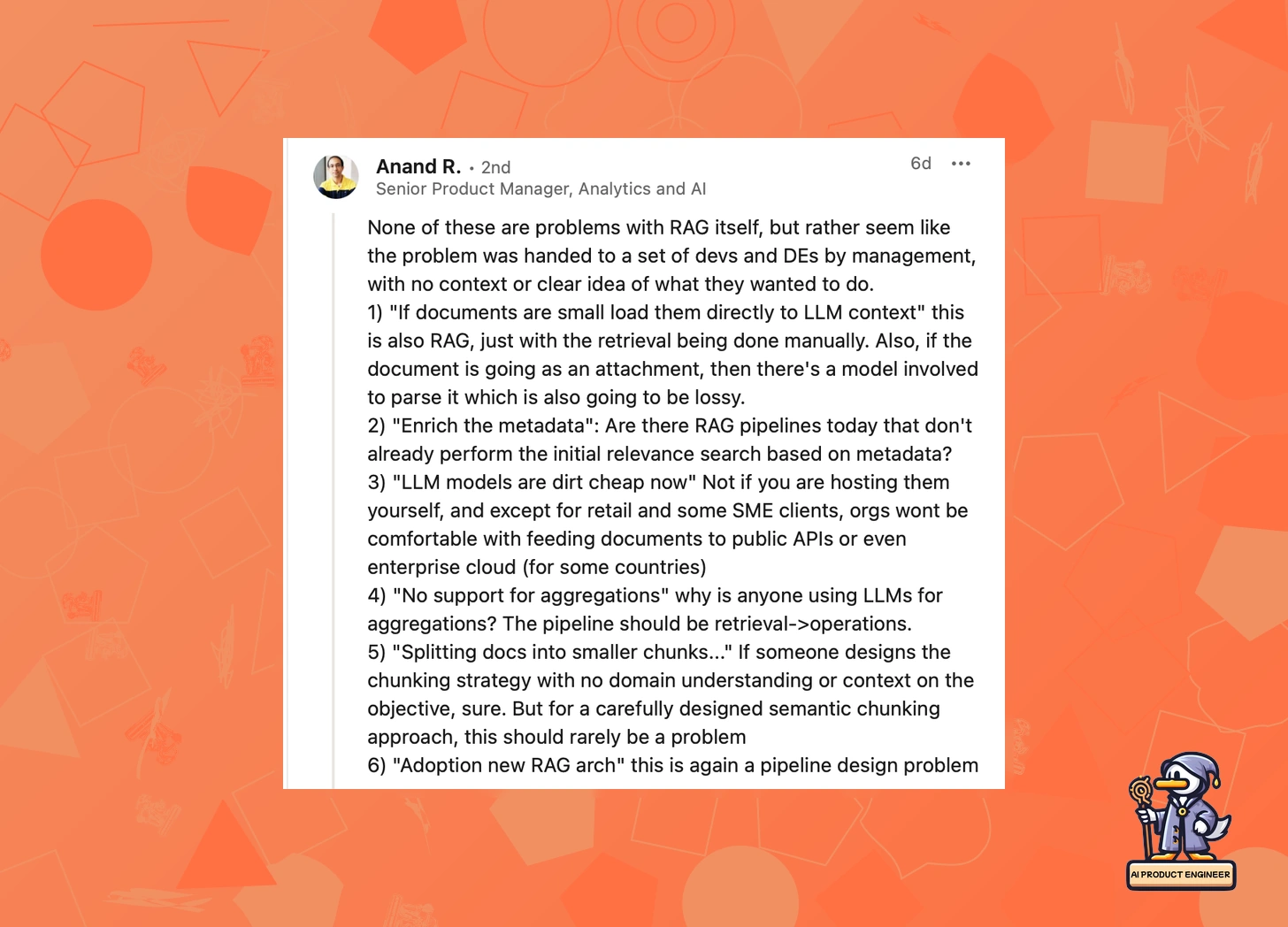
The RAG defenders made relevant counterpoints. Anand Ramani systematically broke down Richard's examples, arguing that these failures stemmed from poor implementations rather than inherent flaws in RAG itself. As he put it, "These aren't problems with RAG—they're problems with vague objectives handed to developers with no clear strategy."
Even more telling were the voices of those successfully using RAG in production. They're not claiming it's perfect, but they're seeing solid results with hybrid approaches—combining vector search with keyword matching, leveraging semantic chunking, and incorporating metadata effectively. The message? RAG isn't the problem—bad RAG implementations are.
As Luca Regini pointed out when done right—with hybrid search, well-structured chunking, and good metadata—RAG works just fine. Some suggested GraphRAG as a promising alternative, though Meng countered that maintaining knowledge graphs presents its own challenges.
Tim Rietz offered perhaps the most balanced take: "Long-context models help, but they won't replace RAG entirely. It might work for a few small documents, but scale that to a company managing tens of thousands of files with hundreds of pages each? It's absurdly inefficient and still prone to hallucinations."
This debate has been unfolding since last year as LLM context windows started expanding rapidly. With models like Gemini now handling up to 2M tokens, some are questioning whether traditional RAG architectures are about to be disrupted. But does that mean RAG is dead? This was the heated subject of discussion in our second topic.
I'll continue formatting the rest of the text in markdown, highlighting key points in bold:
2️⃣ Did Google Just Kill RAG?
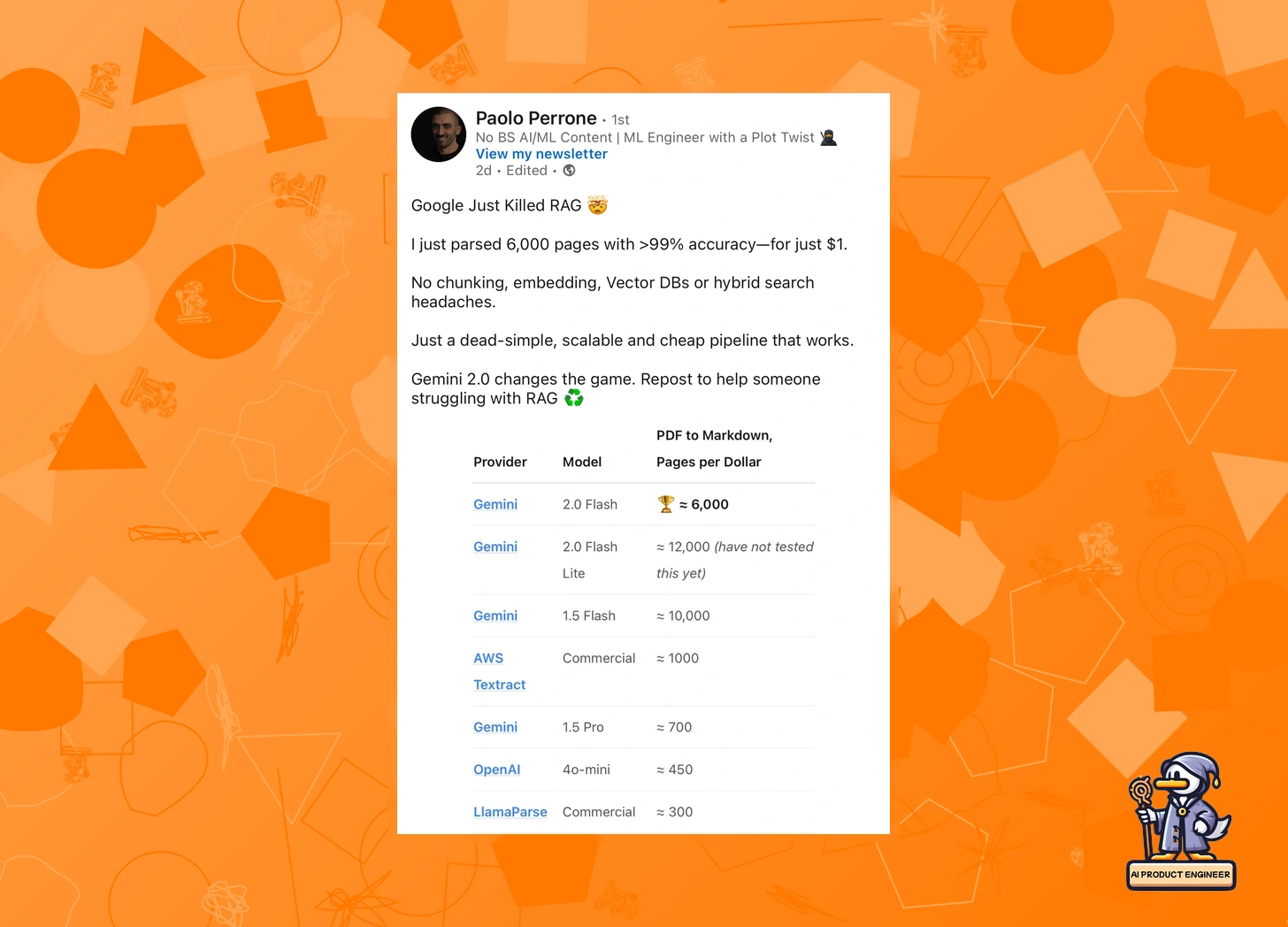
Just as the dust began to settle from Richard's critique, Paolo Perrone stirred the pot with a bombshell post: "Google Just Killed RAG 🤯"—the claim came from a blog post where the author says to have parsed 6,000 pages with >99% accuracy for just $1 using Gemini 2.0.
The post went viral, but the comments section quickly turned into a battlefield between RAG traditionalists and "just stuff it in the context window" revolutionaries.
Paolo's argument? With Gemini 2.0's massive context window and dirt-cheap pricing, why bother with RAG's complexity? No chunking, no embeddings, no vector DBs—just raw LLM power.
But as with Richard's claims, the devil is in the details, and it is always in the details. As we pointed out in the thread, some critical questions remain unanswered: What kind of documents? How complex were they? What specific queries were tested? These are the details that separate a flashy demo from a production-ready solution.
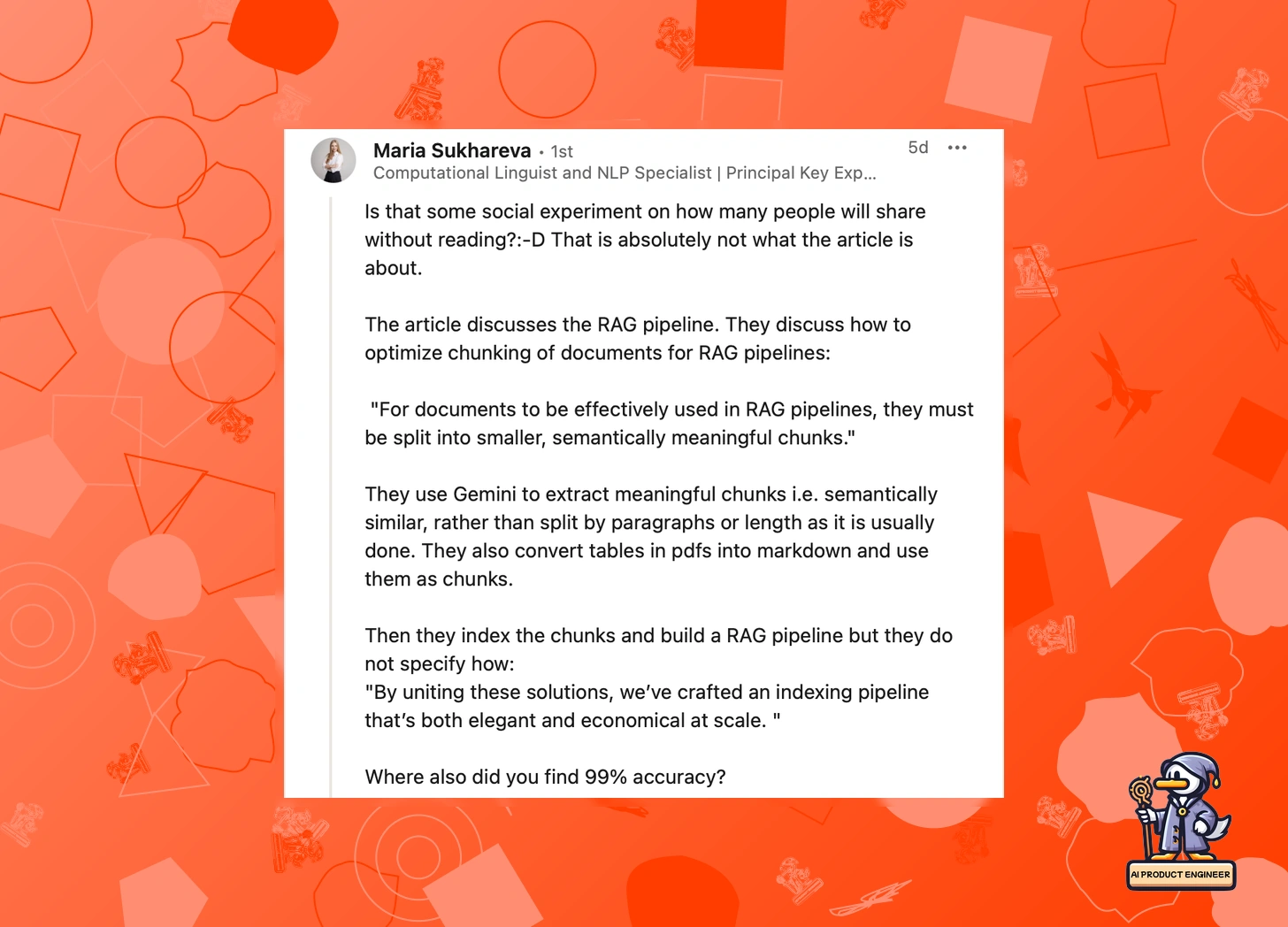
The strongest pushback came from those running RAG in real-world applications. Maria Sukhareva noted that the original study wasn't about replacing RAG but optimizing it. Others pointed out that while Gemini's context window is impressive, it's far from a silver bullet for enterprise-scale document processing.
What's emerging is a more nuanced picture: Maybe the real question isn't whether RAG is "dead" but rather when and how to use different retrieval strategies. As one commenter put it, "RAG isn't going anywhere—the market is big enough for multiple approaches."
Richard's critique highlights RAG's implementation challenges, while Paolo showcases the potential of large context windows. But the future likely lies in a hybrid approach, where RAG, direct context loading, and other techniques coexist depending on the use case.
The real game-changer isn't the death of RAG—it's having more tools in our AI engineering toolbox. And maybe that's exactly what we needed all along. Which we might as well need, as our next topic shows.
3️⃣ The Long Context Illusion: Why RAG Isn't Going Anywhere
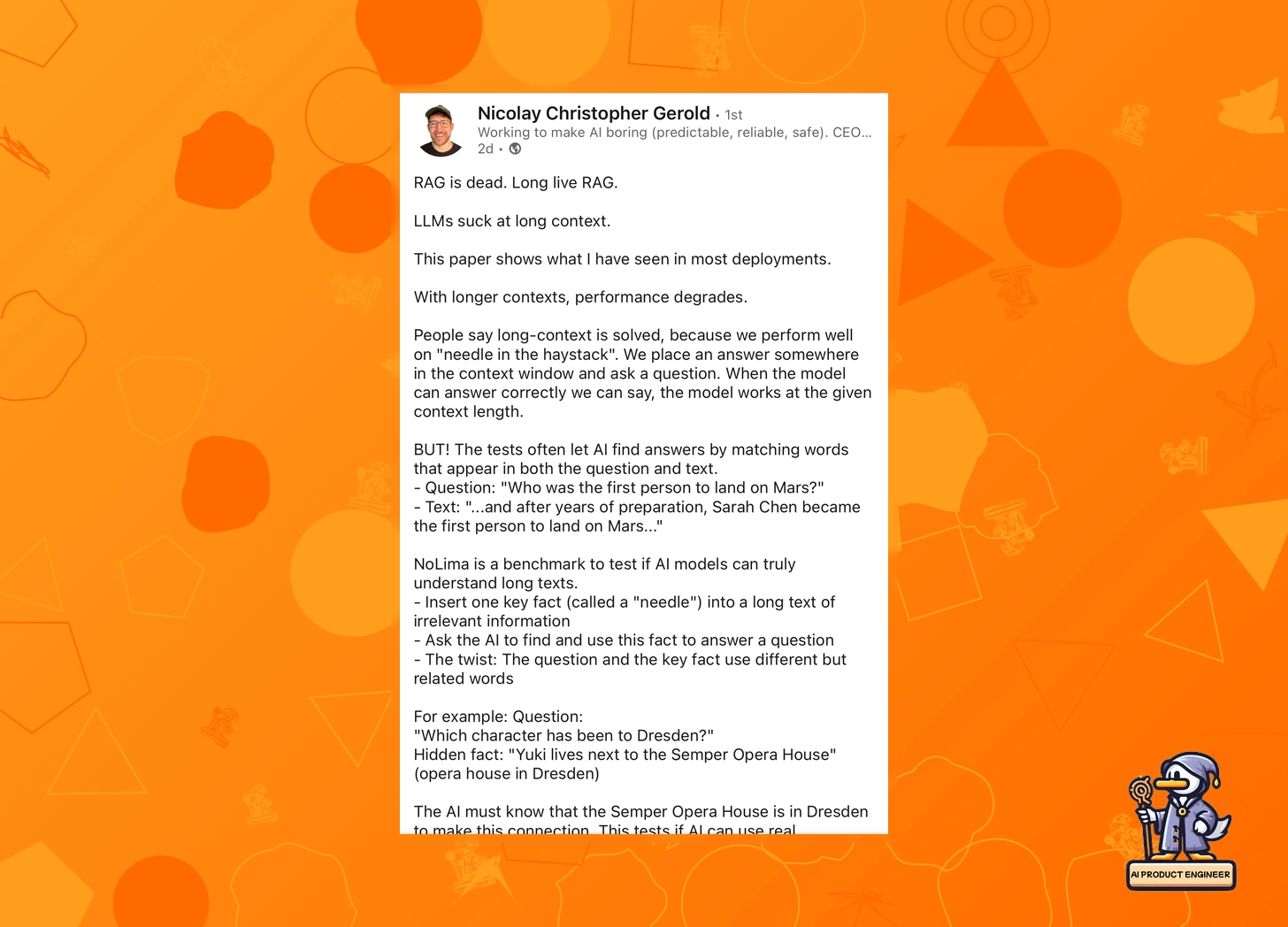
Just when the RAG debate was hitting its peak, Nicolay Christopher Gerold dropped a crucial reality check: Long context windows aren't the silver bullet they're made out to be.
Remember Paolo's claim that Gemini 2.0 "killed RAG" by parsing 6,000 pages for a dollar? Or Richard's insistence that RAG is a failure? Turns out, there's a major flaw in both perspectives.
Nicolay points to the NoLima benchmark, which reveals a sobering truth: even our best LLMs start falling apart when dealing with long contexts. Not just minor degradation—performance can drop to 20% accuracy at 32K tokens (roughly 30-40 pages). Nowhere near the dream of million-token context windows solving all our problems.
Crucially, NoLima doesn't just test for "needle in a haystack" retrieval. It checks real reasoning—like whether a model can connect "lives next to the Semper Opera House" with being in Dresden. And right now? They struggle. Badly.
As we pointed out in the thread, this has massive implications. If models break down at 32K tokens, what happens when you dump a 500-page document into a 2-million token context? It's not just about fitting the text—it's about whether the model can actually understand it.
So where does this leave us? Somewhere far more nuanced than "RAG is dead" or "just do it better." The real takeaway? We need both intelligent retrieval and smart context management. As one commenter put it, "The real question isn't whether RAG is obsolete, but rather when and how to use different approaches."
The future likely belongs to hybrid models—using RAG for efficient filtering while leveraging long-context LLMs for deeper analysis. Why force a model to drink from a firehose when you can serve it a carefully curated glass of water?
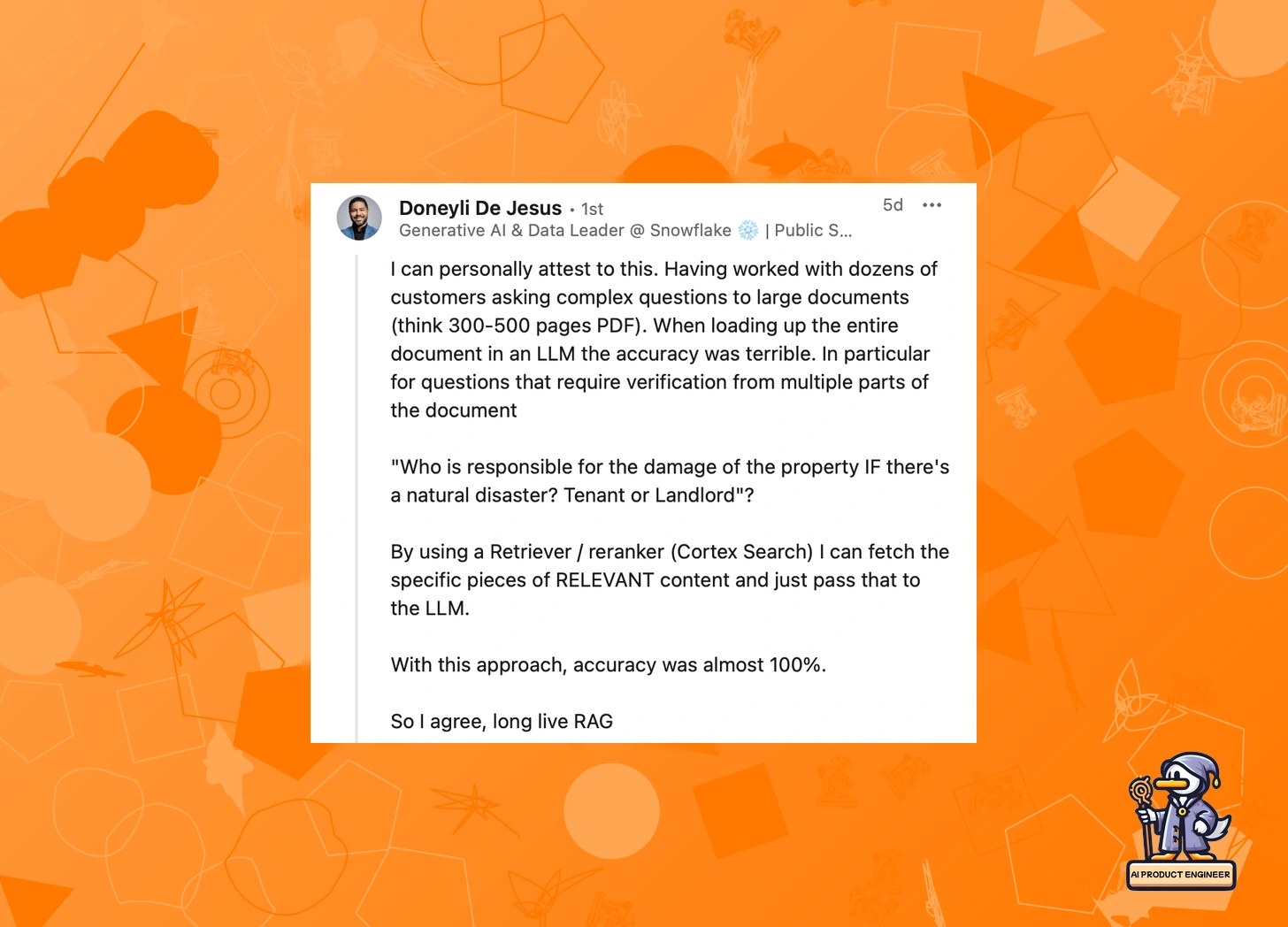
This theoretical concern isn't just academic—practitioners are seeing these limitations firsthand. Doneyli De Jesus reports significant accuracy problems when loading entire documents (300-500 pages) into LLMs. He shares a telling example:
"When testing questions that require verification from multiple parts of a document, like 'Who is responsible for property damage during natural disasters—tenant or landlord?',
loading the entire document led to poor results. However, using a Retriever/reranker to fetch specific relevant content first achieved nearly 100% accuracy."
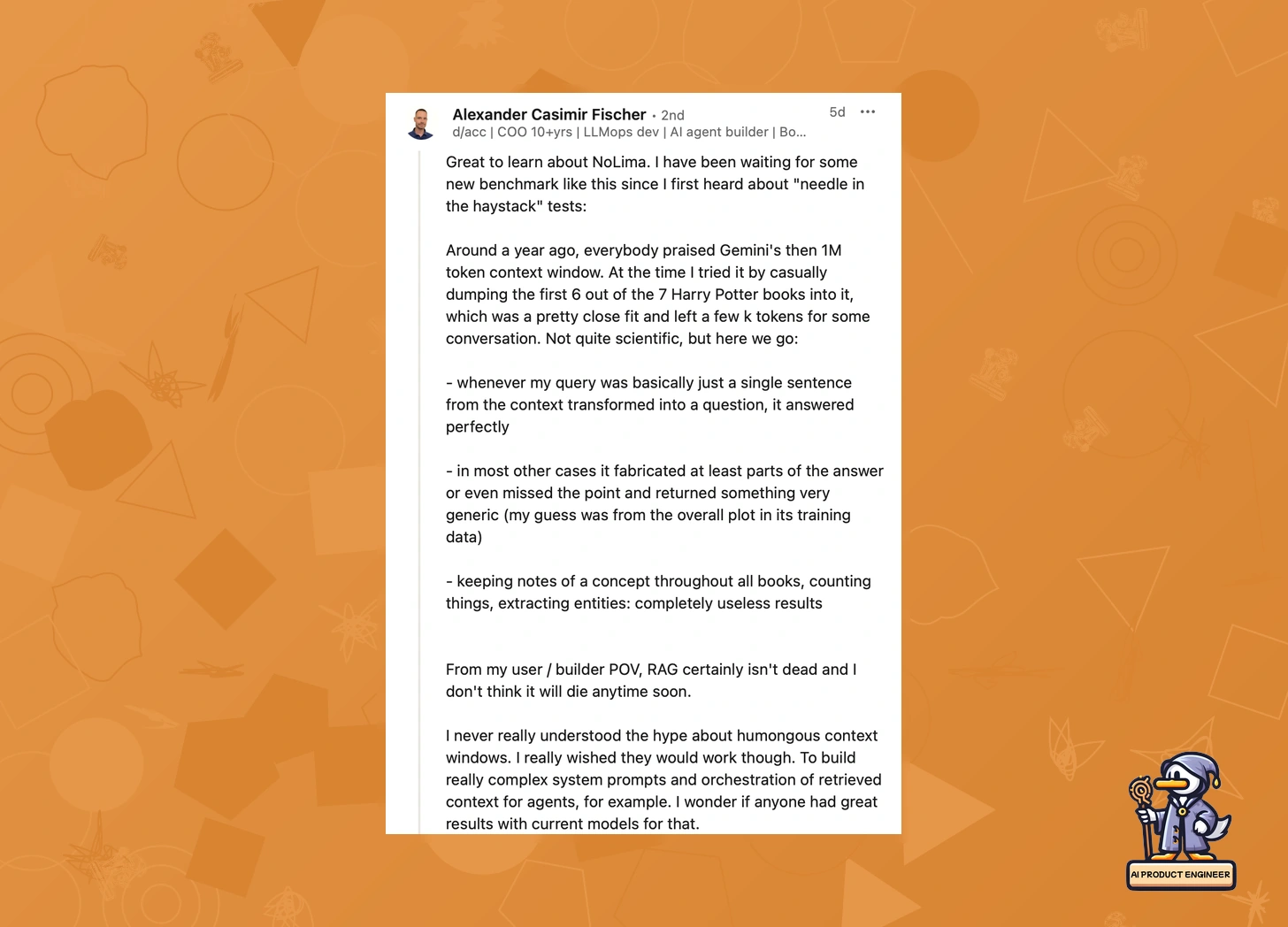
Alexander Casimir Fischer's experiments provide further evidence. His tests with Gemini's 1M token context window, using the first six Harry Potter books as input, revealed crucial limitations:
Perfect accuracy for simple quote-based questions
Fabricated answers and generic responses for complex queries
Complete failure at tracking concepts across books or performing comprehensive analysis
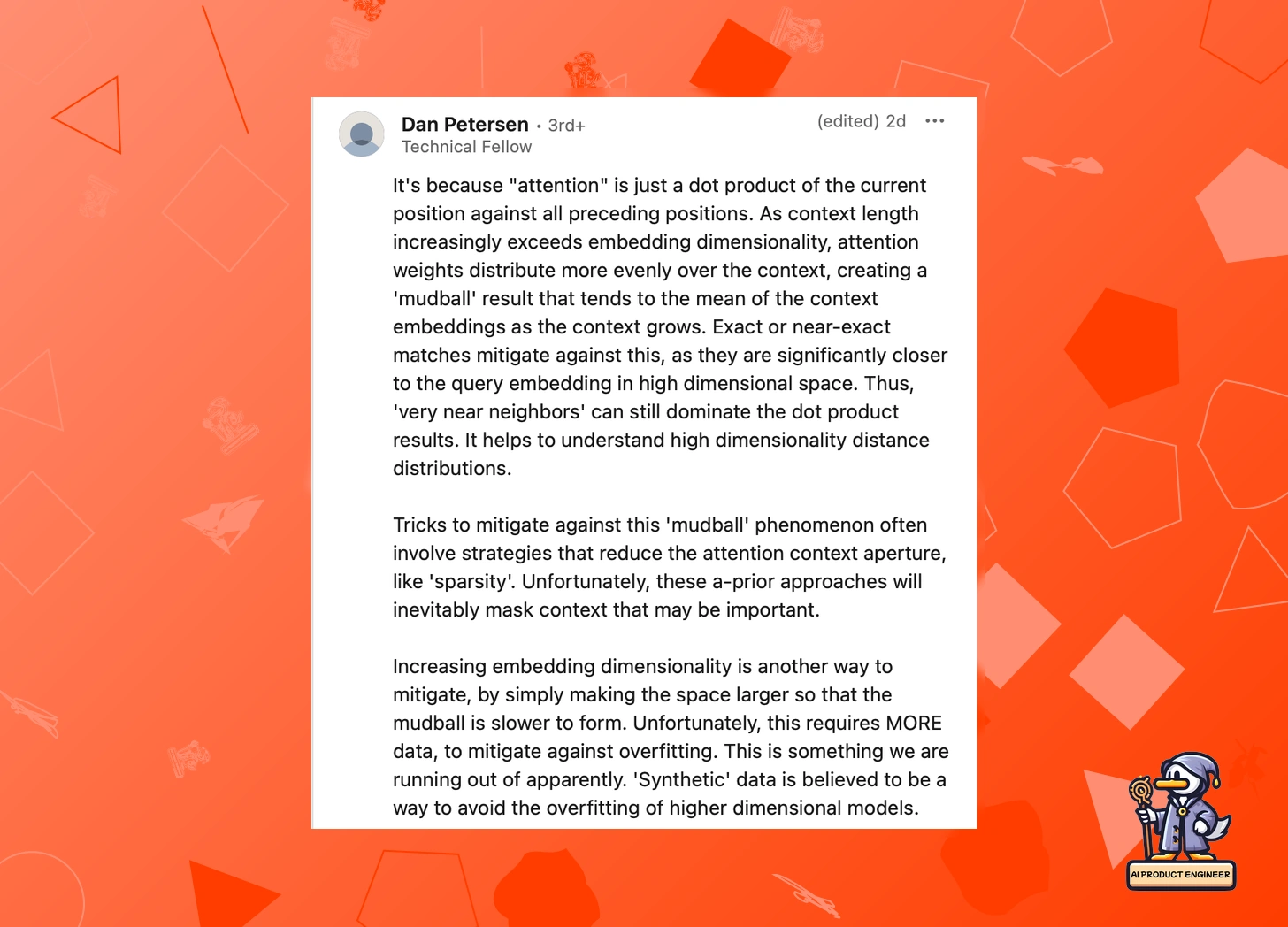
But why do these limitations exist? Dan Petersen offers a technical explanation:
"'Attention' is just a dot product of the current position against all preceding positions. As context length increasingly exceeds embedding dimensionality, attention weights distribute more evenly over the context, creating a 'mudball' result."
This "mudball effect" explains why models can still handle exact matches well, but struggle with nuanced reasoning across long contexts. While there are potential solutions—like increasing embedding dimensionality or using sparsity techniques—each comes with its own trade-offs and data requirements.
Last week's RAG debate has sparked intense discussions, but the takeaway is clear: neither side has an absolute answer. While long-context LLMs are improving, they aren't magic solutions. RAG, when properly implemented, still provides valuable retrieval and structuring capabilities, particularly for large-scale enterprise applications.
Rather than framing this as "RAG vs. LLMs," the real question is how to blend these approaches effectively. Hybrid strategies that balance retrieval with structured context management will likely define the next generation of AI-powered document processing.
Instead of declaring RAG dead, we should be asking: How do we make it better?
Conclusion
The last week of RAG debates made one thing clear: there's no one-size-fits-all solution to document retrieval. While long-context models are improving, they still struggle with accuracy degradation, making them unreliable for large-scale document processing. RAG, on the other hand, is often dismissed too quickly due to poor implementations rather than actual limitations.
Richard's claim that RAG is universally failing ignores the fact that many teams are successfully using it—when done right. Paolo's assertion that Gemini 2.0 has rendered RAG obsolete overlooks the practical constraints of long-context models at scale. And Nicolay's insight into model performance degradation underscores the fact that hybrid approaches will likely define the future of retrieval.
Instead of arguing whether RAG is dead, the real discussion should be about when and how to use RAG effectively. Whether it's through improved chunking, hybrid retrieval techniques, or integration with long-context models, the answer isn't to abandon RAG—it's to refine and optimize it for the real-world challenges AI engineers face today.
And regardless if you want to build RAG applications or you just start learning about AI, remember to subscribe to our newsletter at newsletter.aiproduct.engineer and follow us across social media under @aipengineer
Until next time!